


Devil in the grooves: The case against forensic firearms analysis
A landmark Chicago court ruling threatens a century of expert ballistics testimony


Last February, Chicago circuit court judge William Hooks made some history. He became the first judge in the country to bar the use of ballistics matching testimony in a criminal trial.
In Illinois v. Rickey Winfield, prosecutors had planned to call a forensic firearms analyst to explain how he was able to match a bullet found at a crime scene to a gun alleged to be in possession of the defendant.
It’s the sort of testimony experts give every day in criminal courts around the country. But this time, attorneys with the Cook County Public Defender’s Office requested a hearing to determine whether there was any scientific foundation for the claim that a specific bullet can be matched to a specific gun. Hooks granted the hearing and, after considering arguments from both sides, he issued his ruling.
It was an earth-shaking opinion, and it could bring big changes to how gun crimes are prosecuted — in Chicago and possibly elsewhere.
Hooks isn’t the first judge to be skeptical of claims made by forensic firearms analysts. Other courts have put restrictions on which terminology analysts use in front of juries. But Hooks is the first to bar such testimony outright. “There are no objective forensic based reasons that firearms identification evidence belongs in any category of forensic science,” Hooks writes. He adds that the wrongful convictions already attributable to the field “should serve as a wake-up call to courts operating as rubber stamps in blindly finding general acceptance” of bullet matching analysis.
For more than a century, forensic firearms analysts have been telling juries that they can match a specific bullet to a specific gun, to the exclusion of all other guns. This claimed ability has helped to put tens of thousands of people in prison, and in a nontrivial percentage of those cases, it’s safe to say that ballistics matching was the only evidence linking the accused to the crime.
But as with other forensic specialties collectively known as pattern matching fields, the claim is facing growing scrutiny. Scientists from outside of forensics point out that there’s no scientific basis for much of what firearms analysts say in court. These critics, backed by a growing body of research, make a pretty startling claim — one that could have profound effects on the criminal justice system: We don't actually know if it's possible to match a specific bullet to a specific gun. And even if it is, we don't know if forensic firearms analysts are any good at it.
The problem with pattern matching
To understand why Hooks’s ruling is so important, we need to delve into some background.
Forensic firearms analysis, or ballistic matching, falls under a category of forensics called toolmark identification, which itself falls under a broader category called pattern matching.
In pattern matching specialties, analysts typically look at a piece of forensic evidence taken from a crime scene and compare it to another piece of evidence linked to a suspect. So they might compare a hair from a suspect’s head to a hair found at the crime scene; a bite mark found on the victim’s body to a suspect’s teeth; or shoe prints to a suspect’s loafers.
Pattern matching analysts then typically make one of three determinations: the two items are a match, the evidence from the accused can be excluded as the source of the evidence found at the crime scene (not a match), or there isn’t sufficient data to make a determination (inconclusive).
In the subfield of toolmark identification, analysts attempt to determine if a mark linked to the crime scene was created by a piece of evidence linked to a suspect. Technically, bitemark analysis is a form of toolmark analysis (the teeth are the “tool”). Toolmark analysts might also try to match knife wounds to a specific knife, the marks on a door or door frame to a specific pry bar or screwdriver, or the marks on a bullet or shell casing to a specific gun.
Pattern matching forensics has a dubious history. Perhaps the most notorious example is the Mississippi dentist Michael West, who in the 1990s and 2000s claimed he could use a fluorescent light to find marks on skin that no one else could see. West claimed to have found otherwise invisible bite marks on victims' bodies, or marks on suspects’ hands that could only have come from gripping a specific knife, or from grasping a victim’s specific purse strap. He sometimes claimed to have found these marks weeks after the incident that allegedly created them. West even once claimed he could match the fingernail marks on a suspect’s back to the fingernails of the victim. He “tested” his theory by prying the fingernails off the dead victim, putting them on sticks, using the sticks to scratch fresh skin, and then “matching” the two sets of fingernail scrapes.
Defenders of these fields argue that analysts like West are aberrant rogues, and not representative of analysts today. But West was considered a pioneer in his day, and the fact that courts continued to certify charlatans like him as expert witnesses ought to tell us something about their ability to distinguish credible expertise from quackery.
Some of the problems in pattern matching are specific to particular fields, but two core criticisms apply across the board. The first is that these fields are entirely subjective. Pattern matching largely boils down to an analyst “eyeballing” two pieces of evidence, then deciding if they're a match. Unlike, say, identifying a blood type or matching a car to registration records, there are no objective criteria in pattern matching. There are no ground truths to find. There are no numbers to crunch.
The second overarching problem is that in most of these areas of analysis, we don’t know how often the distinguishing characteristics used to determine a “match” occur across the broader population of the thing being examined. For example, we don’t know what percentage of the human population’s teeth are capable of leaving a certain pattern of marks on human skin. We don’t even know if such a calculation is even possible. And if it were possible, we don’t know that human skin is capable of recording and preserving bite marks in a way that’s useful (the studies that have examined this suggest it isn't). The characteristics of a bite mark could be affected by the angle of the biter’s teeth, whether the victim was pulling away at the time of the bite, the elasticity of the victim’s skin, the rate at which the victim’s body heals, and countless other factors.
Similarly, we can’t say what percentage of pry bars are capable of leaving a series of scratches on a door. In many cases, both the tool and the substance on which it recorded marks could be affected by an almost endless number of variables. The marks on a door frame might have been created by the screwdriver or pry bar found in the suspect’s home, but there’s no scientific basis to claim the perpetrator couldn’t have used a different screwdriver, pry bar, or a boundless list of other items.
To get a feel for the subjectivity of these fields, we can contrast them with DNA. A typical DNA test looks at a number of markers — typically 16 to 20 — and the sequence of genes present at those markers. Because we know how often a particular sequence occurs at each marker across the human population, we can calculate the odds of anyone other than the suspect having the same DNA sequence found at those markers. If a DNA sample has degraded to the point where analysts can’t use all 20 markers, they can adjust the percentages accordingly. We can calculate a specific margin for error — the odds that a particular hair, skin cell, or sperm cell belongs to anyone other than the defendant, and then relay that information to the jury to inform their deliberations.
We can’t generate a margin for error in the pattern matching fields because we don’t know the frequency with which any of these allegedly distinguishing characteristics occur. Therefore, we can’t estimate the odds that anyone other than the suspect may have left that evidence. We can only rely on the opinions of expert witnesses and their ability to eyeball it.
For most of these cases, there will never be a ground truth to definitively show if the expert was right or wrong. So juries can't even look at experts’ track records to assess their credibility. Because of this, juries end up weighting expert credibility with other, less rational factors. We know from research, for example, that juries tend to trust prosecution experts more than defense experts. Juries also tend to find certainty more persuasive than circumspection, which becomes a problem when an expert is willing to provide that certainty even when there’s insufficient science to justify it.
For decades, judges took the assertions of pattern matching analysts at face value. It wasn’t until DNA testing started showing that some analysts had sent innocent people to prison that scientific organizations began to scrutinize these fields, and started testing some of their underlying premises.
When these scientific groups did take a hard look at these disciplines, they found them lacking. Studies and statements from the National Research Council (NRC) in 2008, National Academies of Science (NAS) in 2009, the Texas Forensic Science Commission (TFSC), and the President’s Council of Advisors on Science and Technology (PCAST) in 2016 have all broadly cast doubt on the validity of pattern matching fields. Numerous other studies have questioned the foundations of specific fields, from bite marks, to fingerprints, to handwriting analysis.
Practitioners of these fields and their defenders in law enforcement and prosecutors' offices have generally responded to such criticism not with humility or regret, but by pushing back, sometimes belligerently and dishonestly. And unfortunately the courts have mostly followed their lead.
The wave of DNA exonerations that began in the early 1990s should have prompted the courts to thoroughly reevaluate every forensic field that has contributed to a wrongful conviction — and certainly any individual analyst who has done so. Instead, while DNA can still be powerful enough to overturn a conviction, the system has largely failed to reckon with what these exonerations mean for the rest of the criminal justice system.
If you were wrongly convicted of rape because of testimony from, say, a dubious carpet fiber analyst, but your lawyer found some DNA from the rape kit that can be tested, you may be in luck. But if the rape kit was improperly preserved, or if testimony from that same analyst convicted you of, for example, a robbery or some other crime for which DNA is unlikely to be a factor, you’re probably out of luck.
What we don't know about firearms analysis
Because the courts are so resistant to revisiting cases without DNA, forensic firearms analysis presents an especially difficult challenge for the wrongly convicted. Bite mark, hair, and fingerprint evidence are all biological in nature. This means any evidence that may have been incorrectly matched is likely to include or have been accompanied by DNA. So DNA tests can confirm or refute the analyst’s conclusions.
Bullets aren’t biological in nature. Moreover, when someone is shot from a distance, the assailant isn’t as likely to leave DNA behind. For this reason, the more important the ballistics evidence is to a wrongful conviction, the less likely it is that there is testable DNA, which means it’s less likely that these wrongful convictions will ever be overturned.
Because of this, there have been far fewer exonerations in cases that turned primarily on ballistic analysis than with other pattern matching fields. Still, there have been a few, including Patrick Pursely in Illinois, Anthony Ray Hinton in Alabama, and Keith Davis in Baltimore. The well-publicized trials of Curtis Flowers in Mississippi also relied on ballistics matching, though in that case the state also relied on (also flawed) testimony from eyewitnesses.
Prosecutors and forensic firearm analysts have cited this comparable dearth of exonerations as evidence of the field’s accuracy. But this is misleading. Because firearms analysis is just as subjective and just as prone to human error as other pattern matching fields, it seems likely that a comparable percentage of cases resulted in a wrongful conviction. We’ll just never know about them because they're much less likely to include DNA.
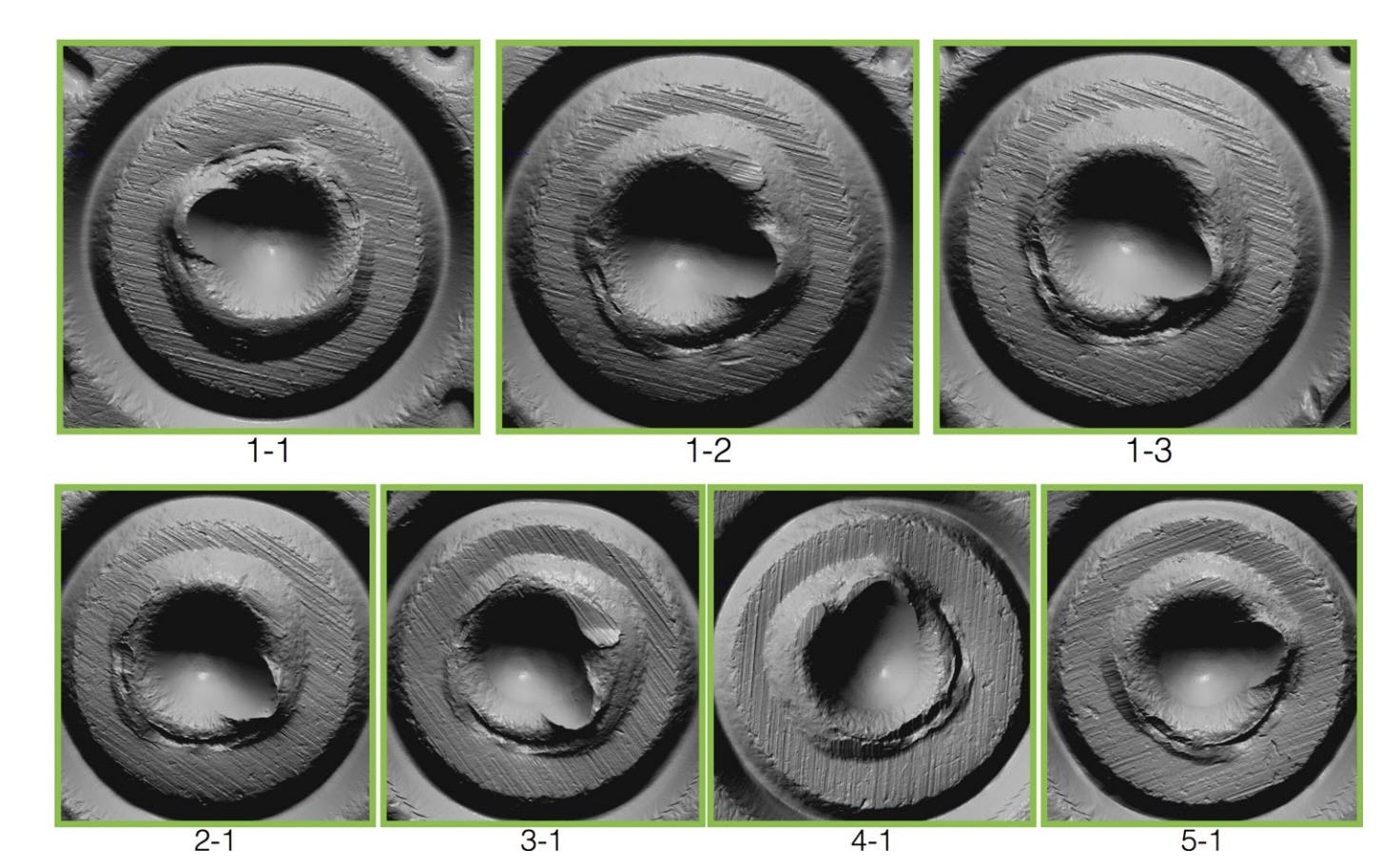
The theory behind matching a specific bullet to a specific gun goes roughly like this:
Inside the barrel of every firearm there are built-in grooves, and the structures between the grooves in the barrel, called lands. The lands and grooves spin the bullet as it leaves the gun. This spinning helps the bullet fly straight. The number of grooves, the space between them, and the direction they spin the bullet are all intentionally cut into the gun during manufacture. They’re part of the gun's design.
These, along with the make and caliber of the bullet, are known as "class characteristics.” They’re easily identifiable features that are shared by large groups of guns. Class characteristics aren’t all that objectionable, and they can be used to eliminate or exclude suspects — the gun isn't a make or model capable of firing the caliber of bullet in question, it spins bullets in the opposite direction, or it leaves fewer grooves. It’s a little like saying you can exclude a suspect because the hairs found at the crime scene were blonde, and the suspect has black hair.
But every gun also has structural imperfections inside that create tiny, often microscopic marks on bullets. These are not part of a gun’s intentional design.
Forensic firearms identification rests on the premise that these imperfections in the barrel of every gun are unique, and therefore every gun leaves marks and striations on every bullet that are unique to that gun. These are called individual characteristics.
Proponents of firearms analysis claim that with a microscope, a well-trained analyst can examine these marks and determine if two bullets were fired by the same gun. So if police find a gun in a suspect’s home that fires the same type and size of bullet found at the crime scene, an analyst will fire one or more test bullets from that gun, then compare the marks on the test bullets to the bullet found at the crime scene.
The process is similar for identifying casings. This is the portion of a round of ammunition that contains the explosive material that propels the bullet. When a gun's firing pin strikes the casing, the impact causes a small explosion which launches the bullet. The gun then ejects the casing. As with bullets themselves, firearms analysis of casings rests on the premise that in the process of striking the casing with a firing pin and then ejecting it, each gun leaves a unique set of microscopic marks.
The problem is that we don’t really know if any of these claims about individual characteristics are actually true. We don’t know if the lands in each gun barrel leave unique marks on bullets that can’t be replicated by other guns. We don’t know if a gun’s firing pin and ejection mechanism leave unique marks on a casing. We don’t know the frequency with which specific marks may appear among the entire population of fired bullets. We also don’t know how to account for the likelihood that a gun will leave different sorts of marks on bullets over the course of its life as a functioning gun as the ridges and grooves inside the barrel wear down — an issue that would presumably affect older cold cases.
Because we don't know any of this, we can’t generate a margin for error for the marks on bullets and casings the way we can with DNA.
Nevertheless, like other pattern matching specialists, forensic firearms analysts regularly testify that a particular bullet is a match to a particular gun, often with haughty language like “to a reasonable scientific certainty,” “to a reasonable ballistics certainty," or they’ll say it’s a "practical impossibility" that any gun other than the gun in question fired a particular bullet.
It’s language that sounds technical and resolute, and juries find it persuasive. But phrases like “reasonable scientific certainty” aren’t quantifiable, so they have no real meaning.
Cook County Assistant Public Defender Richard Gutierrez expounded on this problem in the brief he wrote for the hearing in Chicago:
. . . no empirical thresholds or minimums guide these decisions (i.e. there are no set number of agreements or disagreements necessary to justify an identification or elimination conclusion). Instead, the field’s main guidance document indicates only that examiners should utilize their “subjective” judgment / “training and experience” to evaluate whether they have observed “sufficient agreement” of individual characteristics . . .
Despite the subjectivity involved, when an examiner renders an “identification” conclusion, they may opine that the potential for error “is so remote as to be considered a practical impossibility.”
Even if we were to assume that each gun does leave unique marks on each bullet it fires, there's the matter of whether forensic analysts are actually any good at matching them to a specific gun. For decades, no one bothered to check. That has begun to change, and so far the results aren’t encouraging.
All of this is why, 14 years ago, a National Research Council study of firearms analysis concluded, “the validity of the fundamental assumptions of uniqueness of reproducibility of firearms-related toolmarks has not yet been fully demonstrated." And the following year, the landmark National Academy of Sciences report on forensics concluded, “sufficient studies have not been done to understand the reliability and reproducibility of the methods” of firearms analysts. Then, six years ago, the PCAST report wrote of ballistics matching, “ . . . the current evidence still falls short of the scientific criteria for foundational validity.”
Yet these critiques from the scientific community genearlly haven’t swayed the courts. In our criminal justice system, the U.S. Supreme Court and state appellate courts have designated trial judges the gatekeepers of good and bad science in the courtroom. The problem is that judges are trained as lawyers, not as scientists. So they tend to decide challenges to expert testimony with a legal analysis instead of a scientific one.
Rather than looking at whether a field of forensics survives scientific scrutiny, they’ll simply look at what other courts have already said on the matter — they’ll look to precedent. It only takes a few courts to certify a dubious field of forensics to create a nearly impenetrable wall of bad case law, thus ensuring other courts will continue to get it wrong for years to come.
Because it's now widely recognized to be junk science, bitemark analysis provides a useful illustration. The first appellate court opinion in the country to approve bitemark evidence in a criminal case was a California appeals court in 1975. The majority approved bitemark analysis in that particular case as an exercise in “common sense.” Another appeals court then mis-cited that ruling, claiming the court had found bitemark analysis to be rooted in science. Other courts then cited that court, more courts cited those courts, and so on, until dozens of courts had created a a considerable body of case law attesting to the scientific validity of a field that had yet to be evaluated by any actual scientists.
Still today, there are states in which the controlling precedent establishing bitemark evidence as scientifically valid is a case in which the analyst was provably wrong, and the defendant was later declared innocent and exonerated. And even now, only a handful of courts have ruled the evidence to be unreliable.
But bitemark analysis has only been around since the 1970s. Courts have been using ballistics analysis for more than a century. This presents a more daunting challenge for critics. For courts to overturn forensic firearms evidence now would require judges to conclude that the entire criminal legal system has been wrong about a key component of criminal convictions for more than a hundred years. It would call into question not just firearms analysis and the many, many cases in which it was used, but the very way courts have been certifying experts for most of U.S. legal history. It could also be cause to reopen thousands of old cases. And it would make shootings more difficult to prosecute going forward.
None of these are morally persuasive reasons to continue allowing unscientific evidence to corrupt criminal trials. But they are formidable, real-world barriers to stopping it. Overcoming them will require judges who not only possess the scientific acumen to do a proper analysis, but who can summon the courage to buck decades of precedent. It will take judges willing to ask the sorts of questions that could undermine thousands of convictions spanning decades of criminal trials, and call into question the very legitimacy of the system within which they’ve built their careers.
Whose opinion matters?
In researching this piece, I learned something that after 20 years on this beat still managed to astonish me.
Over the last 15 years or so, we’ve seen numerous scandals in which prosecutors and crime lab analysts failed to disclose test results that exculpated or even exonerated defendants.
This has commonly been found in drug or DUI cases, but we’ve seen it in other areas, too. For example, prior to DNA testing there were dozens of cases which analysts discovered that blood found at a crime scene was of a different type than that of either the victim or the defendant, but told a court the results were “inconclusive.” If this was blood found, say, under the victim's fingernails, such a finding could be powerful exculpatory evidence.
It's difficult to know how often this has happened, and it’s likely more frequent than officially acknowledged, but these scandals were at least recognized as scandals, and in most fields of forensics, failing to disclose exculpatory test results is acknowledged as both unethical and a violation of a suspect’s constitutional rights (even if officials aren’t always eager to do much about it when it happens).
But this isn't the case with firearms analysis. Before this piece, my assumption had been that analysts give an “inconclusive” designation when a bullet is so mangled or fragmented that it becomes impossible to identify any of its individual characteristics.
So here’s the astonishing part: This isn't true. At most crime labs -- including both the FBI crime lab and the Illinois state crime lab that performed the analysis in the Cook County case -- ballistics analysts will “match” a bullet to a gun, but they will not “exclude” a particular bullet from having been fired from a particular gun as a matter of policy. Just to be clear: Their official policy is that they will utilize the alleged uniqueness of these microscopic marks to send someone to prison, but not to exonerate someone.
Their reasoning for this is spurious. They say that depending on the circumstances, a specific gun could potentially leave decidedly different marks on different bullets over its lifetime of use. So it’s impossible for them to definitively say one specific gun couldn't have left a specific series of marks.
That seems perfectly reasonable — until you remember that when these same analysts match a specific bullet to a specific gun, they are, by definition, excluding every other gun on the planet.
They refuse to exclude one specific gun if it would benefit the defense, but they're willing to exclude every gun in existence but one to benefit the prosecution. And this isn't the secret, unstated policy of a few rogue analysts. It's the official policy of some of the most widely-used and respected crime labs in the country.
"When prosecutors send a bullet and gun to one of these labs for testing, they have nothing to lose," says Chris Fabricant, who has worked on firearms identification cases as director of strategic litigation for the Innocence Project. "At worst, they’ll be told there's insufficient evidence to match the bullet to the gun, at which point they can just fall back on whatever other evidence they may have. But there’s no risk of them hurting their case."
A field that can only benefit the prosecution hardly seems a neutral, objective, science-based field that’s only interested in truth. And the conceit becomes all the more absurd when firearms analysts are challenged in hearings like the one in Chicago.

When one side of a case challenges the validity of expert testimony, the attorneys request a hearing to assess the scientific reliability of that testimony. If the judge grants a hearing (which itself is rare), both sides then call their own experts to argue their side of the dispute.
In most states and in the federal courts, judges evaluate the challenged testimony under criteria laid out by the U.S. Supreme Court in a series of 1990s decisions collectively known as the Daubert standard. Illinois is one of a handful of states that still use the older standard, known as Frye. But for the purposes of this discussion, the differences between the two aren’t critical.
Under both standards, one of the first things a judge needs to do is define the community of scientists whose opinions should be considered. This is a critical decision, because whether a field is credible will often depend on whom you ask. And in the Chicago case, prosecutors wanted Judge Hooks to limit what’s typically called the “relevant scientific community” to other ballistics analysts.
That isn’t unusual. Prosecutors and law enforcement officials tend to deride the scientists who scrutinize these fields as outsiders who have never done a bullet comparison, never taken a dental mold for a bite mark comparison, and so on. Because they aren't practitioners, the argument goes, the scientists have no business standing in judgment.
But once you've decided that the only people whose opinions about a disputed field are the people who practice in that field — and whose livelihood depends on the courts continuing to find it credible — you have all but guaranteed the outcome. It’s like trying to assess the scientific validity of tarot card reading by limiting the relevant scientific community to fellow tarot card readers. (Note: Forensic analysts really hate this analogy.)
This is all especially problematic in ballistics analysis. If ballistics experts work in labs that, as a matter of policy, refuse to exonerate suspects even when their own test results tell them they should, it seems absurd to say that judges should consult those same experts — and only those experts — when adjudicating whether the field is credible, fair, and scientifically sound.
That may seem like a fairly intuitive position, but it was far from guaranteed that Hooks would reach the same conclusion. Most challenges to forensic testimony don’t even result in a hearing, and in many of those that do, judges don’t bother with the "relevant scientific community" question. More commonly they just cite what other courts have said.
Finally, even among those courts that have entertained the question, they’re likely to agree with prosecutors and limit the inquiry to whether a particular expert is considered credible by other experts in the field, instead of whether the field itself is credible.
But Hooks made it clear early on that this case could be different. When he first granted the hearing, he explained that he would be considering the opinions of scientists outside the world of forensic firearms analysis. And given the consistent criticism of the field from the broader scientific community, that decision alone gave a good indication of where he'd come down.
The road to Chicago
In deciding to take on ballistics matching in the Winfield case, the Cook County public defenders knew they faced long odds. Prior to the flurry of scientific studies of forensics in the late 2000s, few defense attorneys bothered to challenge the practice, and most courts accepted ballistics testimony without much pushback. In summarizing the existing case law in a 2007 ruling, for example, the U.S. District Court for the Northern District of California wrote that “no reported [court] decision has ever excluded firearms-identification expert testimony under Daubert."
The 2008 National Research Council report and the 2009 NAS report did spur a handful of courts to impose some minor restrictions on firearms identification, such as barring analysts from using the word “match,” or from claiming that a bullet could only have been fired by a specific gun to the exclusion of all other guns in the world.
But the overwhelming majority of courts continued to reinforce the facade that has allowed analysts to say things like it's a "practical impossibility" that any gun other than the gun in question could have fired a particular bullet -- expressions of certainty that sound impressive, but are scientific gibberish.
Still, a few cracks did emerge. Perhaps most importantly, in 2008 a federal district court in New York ruled that ballistics matching “could not fairly be called ‘science,’” and that therefore, the analyst in that case could go no further than to say it was “more likely than not” that a particular bullet had been fired by a particular gun.
Though isolated, that ruling set off alarms in the ballistics community. As Jim Agar, an attorney for the FBI crime lab, recently wrote in a law review article, “For the first time in American history, a judge ordered an expert witness in the area of firearms identification to make substantive and material changes to their expert opinion and directed the expert to not identify the source of a cartridge case or bullet.” Needless to say, Agar did not consider this to be a positive development.
After the PCAST report in 2015, another smattering of courts added their own restrictions on testimony, including barring analysts from using phrases like “practical impossibility” or “100 percent certain.” Among them:
— In 2017, a federal district court judge in Maryland restricted an analyst from going further than to say a bullet was “consistent with” a particular gun.
— Two years later, another federal judge in Virginia barred an analyst from using the word “match.”

— Also in 2019, the U.S. Court of Appeals for the District of Columbia put out the most restrictive ruling yet from a federal appeals court, finding that a lower court should not have let an analyst say that a bullet could only have been fired by a specific gun.
— Later that year, a D.C. Superior Court judge went farther, ruling that an analyst could only say that he could not “exclude the possibility” that a particular bullet had been fired by a specific gun.
— In 2020 a federal district court in Oregon ruled that because a forensic firearm analyst’s methodology could not be replicated, the analyst could testify only to the class characteristics of a gun and bullet, but not the individual characteristics.
— A few months later, a state court in the Bronx ruled that an analyst could only testify to the make and model of the gun and the caliber and variety of the bullet.
These rulings — the latter two in particular — were significant enough to have rankled firearms examiners and the prosecutors who use them. In a 2022 memo to firearms analysts around the country, FBI crime lab attorney Agar offered a strategy for analysts to combat judges who restrict their testimony, including suggesting they tell judges that to prohibit them from matching one bullet to one gun would be akin to asking them to perjure themselves -- a claim that both scientists and legal ethicists say is preposterous.
But while these rulings are enough to irritate advocates like Agar, they’ve still been relatively rare. The vast majority of courts still allow juries to hear such testimony. According to Agar’s own law review article, in the seven years since the PCAST report, forensic firearms analysis has been upheld by at least seven federal district courts, and appeals courts in at least 14 states.
Hooks's ruling stakes out new ground. It goes further than any court to date by barring the ballistics analyst from testifying at all. His reasoning is grounded in the Illinois rules of evidence and the Frye standard, but also common sense: There's nothing unscientific about testifying to the class characteristics of guns and bullets -- the caliber and make, the broad rifling patterns created by a particular make and model of a gun, and so on. But these are clear, noticeable differences that don’t require much expertise to recognize. It's the matching of individual characteristics that makes a firearms analyst valuable as an expert. And unfortunately, this is the very part of their analysis that lacks scientific support.
"The probative value of the evidence in the instant matter is a big zero . . . if admitted . . . it would imply or suggest the value of such evidence is far beyond what it actually should be viewed as representing. Such evidence would also improperly imply a logical closeness between some immediate fact and the ultimate case issues when nothing could be further from accurate. Therefore, such evidence should be barred based upon the possibility of such misplaced strength inferences that may be drawn simply based upon such admission . . .
The combination of scary weapons, spent bullets, and death pictures without even a minimal connection would create an unfairly prejudicial effect that could lead to yet another wrongful conviction.
The possibility of "confusion of the issues" in the instant matter is not merely a possibility, it's a promise . . . The offered evidence is clearly inflammatory by its inferences and could trigger and encourage irrational and emotional results far beyond simply being incorrect inferences . . . such evidence will be given far too much weight by a jury.
There’s also academic research to support Hooks’s logic. When experts say they “cannot exclude” a piece of evidence as having come from the defendant, jurors tend to understand that for what it means — it’s incriminatory, but only mildly so. Once experts use any terminology suggesting a match — any wording that links the evidence to the defendant individually — jurors tend to assume the defendant is guilty, regardless of phrasing. In fact, the suggestion of a match from an experienced expert can be more persuasive to jurors than exculpatory evidence.
Measuring competence
As I explained above, forensic firearms analysis can’t generate an error rate to express the likelihood that a specific bullet came from a specific gun. But there is another way we could quantify the credibility of these analysts: We could simply test them. Ideally, we’d test them with “black box” texts, exams that accurately reflect their ability to match bullets to guns in the lab.
Historically, pattern matching fields have been resistant to black box tests. In response to growing criticism after exonerations, some specialties began administering their own tests and presenting the results to the courts as proof of their competence. However, to return to our tarot card analogy, a test to assess the competence of other tarot card readers that was designed and administered by tarot card readers will look quite a bit different than a test administered by skeptical scientists.
In many of the practitioner-administered forensic firearms tests participants were given two sets of bullets. Then, using identifying characteristics, they were asked to match each bullet in one set to a bullet in the other set fired by the same gun. The test takers knew that each bullet in Group A had a corresponding match in Group B.
There are few real-world scenarios in which an analyst would be asked to do this. More typically, an analyst is given a single bullet and asked to determine if it is a match to test bullets fired by a particular gun.
Practitioner-administered tests also tend to be easier. They avoid using varieties of guns known to have similar rifling, or using bullets fired by two guns of the same make and model. The ability to make such distinctions in a courtroom is precisely what makes these analysts valuable to prosecutors, so it’s the sort of thing any worthwhile competency test ought to cover.
One almost comical example cited by the defense in Cook County was a test administered by Todd Weller, the state’s own expert witness. When attorneys at the Bronx Public Defender Service obtained a copy of that test, they gave it to six attorneys in their office, none of whom had any training in firearms analysis. Every staffer who took the test passed it “with flying colors.”
This brings up another reason why it's shortsighted to limit the "relevant scientific community" in these disputes to the practitioners of the field in question: The ability to design a relevant and scientific competency test is its own science. It requires its own reserve of knowledge and expertise. Scientific American published a persuasive opinion piece on this point last year.
In the courts, firearms examiners present themselves as experts. Indeed, they do possess the expertise of a practitioner in the application of forensic techniques, much as a physician is a practitioner of medical tools such as drugs or vaccines. But there is a key distinction between this form of expertise and that of a researcher, who is professionally trained in experimental design, statistics and the scientific method; who manipulates inputs and measures outputs to confirm that the techniques are valid. Both forms of expertise have value, but for different purposes. If you need a COVID vaccine, the nurse has the right form of expertise. By contrast, if you want to know whether the vaccine is effective, you don’t ask the nurse; you ask research scientists who understand how it was created and tested.
To design an accurate competency test, you need to account not just for general cognitive bias, but for other types of bias, such as the fact that the awareness that they’re being tested will prompt some analysts to approach the test material differently than they'd approach their daily work. This is why cognitive scientists recommend that when conceiving competency tests for forensic disciplines, design teams consult not just with practitioners of the field being tested, but with research scientists, statisticians, psychologists, and computer scientists.
But the analysts in these fields have been resistant to such tests. It isn’t difficult to understand why. They’re already widely accepted as experts in courtrooms across the country. They have nothing to gain by subjecting themselves to rigorous testing, and everything to lose.
This was the issue at the heart of the hearing in Chicago, and it’s one of the biggest hurdles to challenging firearms analysis. Prosecutors and their witnesses can throw out a litany of practitioner-administered studies that look impressive, and judges -- and often defense attorneys -- will too often lack the expertise to understand or elucidate why those studies are flawed.
For the Cook County hearing, the prosecution brought in Weller, a veteran forensic firearms analyst who is often asked to testify for the state at these hearings.
There's no question that Weller has ample experience and training in firearms analysis. But he does not have much background in research science. During the hearing, Weller mentioned several studies that claimed to find acceptably low error rates among forensic firearms examiners — most below 1 percent. But he did not mention the studies showing higher error rates, and with the exception of two studies (which I'll discuss in a moment), those he did mention were designed and administered by law enforcement officials and forensic firearms practitioners.
Recognizing all of this, Judge Hooks certified Weller as a ballistics expert, but declined to certify him as an expert in error rates or research science. Few other courts have made the distinction.
“ Even the most meticulous, careful, and experienced tarot card reader . . . is still a tarot card reader.”
How not to measure competence
In recent years, two competency tests have come closer than most to meeting the criteria of a true black box test. In 2016, and then in 2020, the FBI and the Department of Energy conducted two better-designed, sufficiently difficult studies commonly called Ames I and Ames II, named for the Iowa laboratory that administered them.
Because both Ames studies claim to show acceptably low error rates among participants (below 1 percent for false positives, and below 3 percent for false negatives), they’ve since been touted by the forensic firearms community, and then by judges when denying challenges to those experts.
But while these tests were closer to what scientists recommend, there were still some critical problems with them — and chief among those problems is a fundamental disagreement over how the tests were scored.
While Weller and the authors of the test claim it shows an error rate of less than 1 percent, Gutierrez and other critics argue that if scored correctly, the real false positive rate for the Ames tests was between 10 and 40 percent.
That’s a massive discrepancy, and probing that discrepancy can help us us see what these these tests are actually measuring.
Recall that when attempting to match a bullet to a particular gun, analysts will make one of three conclusions: the bullet was fired from the gun, the bullet was not fired from the gun, or there is insufficient evidence to draw a conclusion. Different analysts and labs use different terms, and some will break these categories down into subcategories, but for the purpose of this discussion, I’ll use the terms match, exclusion, and inconclusive.
The Ames I study was a sensitivity test for casings. This means that analysts were asked to examine two shell casings and determine if they'd been ejected by the same gun. According to the authors of the study, the analysts’ false positive rate ranged from 0.656 to 0.933 percent, while the false negative rate ranged from 1.87 percent to 2.87 percent.
That sounds encouraging. But upon closer inspection, the test had an inordinate number of “inconclusive” answers -- far more than what would typically be expected. The inconclusive answers were also heavily skewed toward questions that should have resulted in an exclusion — in other words, when the evidence was exculpatory, the analysts were more likely to answer “inconclusive.”
This wouldn’t have been as concerning if the test was also designed to measure analysts’ ability to determine when the evidence is insufficient to say one way or the other. But that isn't what this test was designed to measure.
So while the tests were intended to prompt one of two possible answers, test-takers were allowed to give three.
The question then becomes how to score “inconclusive” answers — answers which, technically, are neither correct nor incorrect.
There are three theories on how such answers should be scored. The first is to count every inconclusive as correct. The second option is to eliminate any "inconclusive" answers from the overall score and calculate the test-taker’s error rate based only on matches and exclusions. The final option is to count "inconclusives" as wrong if, under the prevailing methods, standards, and practices of the profession, analysts should have answered with match or exclusion.
The authors of the Ames I study went with the first option -- they counted every “inconclusive” answer correct. Many research scientists have been highly critical of that decision. The 2022 essay in the Scientific American laid out the problems:
In the Ames I study, for example, the researchers reported a false positive error rate of 1 percent. But here’s how they got to that: of the 2,178 comparisons they made between nonmatching cartridge cases, 65 percent of the comparisons were correctly called “eliminations.” The other 34 percent of the comparisons were called “inconclusive”, but instead of keeping them as their own category, the researchers lumped them in with eliminations, leaving 1 percent as what they called their false-positive rate. If, however, those inconclusive responses are errors, then the error rate would be 35 percent.
Gutierrez offers an analogy that helps explain what’s happening, here:
“Suppose you were given a test to measure your proficiency at math. The test has 100 questions, ranging widely in difficulty, from simple addition and subtraction to advanced calculus and trigonometry,” he says.
Under the scoring system adopted by the Ames I researchers and advocated by the forensic firearms community, you could simply write “inconclusive” for any question you find difficult, and those answers would all be scored as correct. In fact, you could write “inconclusive” for every answer and still score a 100 percent. But few would argue that’s an accurate assessment of your proficiency at math.
Under the second scoring method, your “inconclusive” answers on the math test would not be counted as correct, but they also wouldn't be counted as wrong. They just wouldn't be counted at all. You could answer all of the “1+1”-level questions, answer “inconclusive” for any question for which you weren't completely certain, and still end up with a perfect score. Your score might be 7/7 instead of 100/100, but your “error rate” would still be 0 percent. Here again, this would not be an accurate reflection of your proficiency at math.
The final option is to count inconclusives that weren’t intended to be inconclusives as wrong. This is how Gutierrez and other critics arrived at error rates of 10 to 40 percent.
It's important to note here that in the real world, we want analysts to say when there’s insufficient evidence to reach a conclusion. One of the main criticisms of these disciplines is that analysts too often reach conclusions that aren’t grounded in science, then present those conclusions in court with far too much certainty.
But the point of a proficiency test isn't to prod analysts to be more cautious. It’s to assess how they currently do their jobs, in the real world. These analysts know they’re being tested. They know the tests are an attempt to assess the legitimacy of their field. If they also know any “inconclusive” answer will be scored as correct, there's a big incentive to respond “inconclusive” to any question for which they have the slightest bit of doubt.
We know that in the real world, improper incentives and cognitive bias can nudge analysts toward finding a match. But in the test-taking world, there’s an incentive for caution and circumspection. If the incentives aren’t aligned, the tests aren’t an accurate reflection of these analysts’ real world performance.
The fact that many analysts work for labs that bar finding “exclusions” as a matter of policy further complicates the scoring. Presumably, a significant portion of the 65 percent who answered correctly on “elimination” questions would not have done so if the same two bullets had been presented to them in their day-to-day work. The defense attorneys in those cases would never have been informed that a state analyst had reached an exculpatory conclusion.
Here again, if the tests allow exclusions as a possible answer for an analyst who wouldn’t be permitted to exclude in the real world, the test isn’t an accurate reflection of the analyst’s real-world performance or the analyst’s real-world impact. All the test is really measuring is the analysts’ ability to game the test.
There were similar problems with the second Ames study. In Ames II, participants were tested on bullets themselves, as opposed to casings. Here again, the researchers found impressively low error rates. And here again, those impressive figures evaporate if you score the tests the way most people believe tests should be scored. Again from Scientific American:
Seven years later, the Ames Laboratory conducted another study, known as Ames II, using the same methodology and reported false positive error rates for bullet and cartridge case comparisons of less than 1 percent. However, when calling inconclusive responses as incorrect instead of correct, the overall error rate skyrockets to 52 percent.
That's actually worse than a coin flip.
The best way to test these analysts’ proficiency in their day-to-day work would be, simply, to test them in their day-to-day work. This could be done by occasionally slipping test cases for which the ground truth is known into their work, but in a manner in which they wouldn’t know when they were being tested.
One crime lab has done exactly this. The Houston Forensic Science Center was created in 2012 after a series of forensic scandals resulted in dozens of overturned convictions and shuttering of the city's previous lab. The new lab’s director, Peter Stout, has publicly committed to running the lab on scientific principles. As part of that commitment, he frequently tests his analysts by inserting test cases into their daily work. He also tries to mask the test cases so his analysts don’t know when they’re being tested — he rewards analysts who sniff out and flag a test case with a Starbucks gift card.
For sensitivity tests — in which analysts are asked to determine if two bullets were fired by the same gun — the Houston lab’s firearm specialists had an error rate of 24 percent. For specificity tests — in which analysts are asked to determine if two bullets were fired by different guns — the error rate climbed to 66 percent.
So in the only proficiency test thus far to test analysts as they engage in their day-to-day work —and at a lab that that presumably puts a premium on hiring analysts who are careful and conscientious — they produced error rates that should disqualify them from ever testifying about a “match” in front of a jury.
Other ways ballistics matching falls short short of “science”
There are other problems with the Ames studies. Ames II also evaluated the process of verification -- when a second analyst double-checks the work of the initial analyst. Verification is a form of peer review, which is another critical part of scientific inquiry. And here too, the authors of the study claimed that when they sent the same samples to both the same participants and different participants months later, the analysts satisfactorily reproduced the original findings.
But when research scientists outside of forensics looked at the study's conclusions, they found them puzzling and at odds with the study’s hard data. Here, for example, is an analysis published in the journal Statistics and Public Policy:
The Report’s conclusions were paradoxical. The observed agreement of examiners with themselves or with other examiners appears mediocre. However, the study concluded repeatability and reproducibility are satisfactory, on grounds that the observed agreement exceeds a quantity called the expected agreement. We find that appropriately employing expected agreement as it was intended does not suggest satisfactory repeatability and reproducibility, but the opposite.
The Scientific American essay is more direct:
The most telling findings came from subsequent phases of the Ames II study in which researchers sent the same items back to the same examiner to re-evaluate and then to different examiners to see whether results could be repeated by the same examiner or reproduced by another. The findings were shocking: The same examiner looking at the same bullets a second time reached the same conclusion only two thirds of the time. Different examiners looking at the same bullets reached the same conclusion less than one third of the time. So much for getting a second opinion! And yet firearms examiners continue to appear in court claiming that studies of firearms identification demonstrate an exceedingly low error rate.
Reliability and predictability are key components of accepted science. If you give a group of scientists the same set of facts and ask them to apply the same accepted principles, they should reach identical or similar conclusions. Yet despite a low rate of agreement, the researchers on Ames II claimed the verification process was successful.
There were also issues with the makeup of the studies' participants. Any study aiming to accurately capture the current state of forensic firearms analysis should pick a randomized sample of analysts from crime labs across the country. In an affidavit for the defense, some research scientists searched legal databases for frequently used analysts, and found that less than half of them would have met the strict criteria to be included in the Ames II study. In other words, the pool of analysts tested wasn’t at all representative of the sort of analysts who typically testify in court. Yet the test's results are commonly cited as proof of the entire field’s proficiency.
Finally, there are transparency issues. The Ames I researchers never made their raw data available to other researchers for verification. Posting data is pretty standard practice in research science. The study was was only recently accepted for publication in a peer-reviewed journal, after eight years. The Ames II study has yet to be published, though it's regularly submitted in courts as evidence.
“Our intent in approaching [forensic firearms analysis] is constructive: until the extent of the cancer is identified, treatment cannot begin.”
In other important ways, the field forensic firearms analysis not only hasn’t met the standards of scientific inquiry, it hasn’t really tried.
Take the concept of blind analysis, or the notion that analysts should insulate themselves from information that may bias them toward a particular conclusion. In a blind system, analysts would first be given the crime scene bullet or the test bullet in isolation, at which point they would describe its respective characteristics. They’d then do the same for the other bullet. Only after evaluating each bullet separately would they attempt to compare the two. If the analyst concludes the bullets to be a match, they’d need to explain any inconsistencies between their initial descriptions.
In an ideal world, the analysts might also occasionally be given bullets with similar markings but known to have been fired from different guns — bullets known not to be implicated — to test their accuracy. This is the gold standard with eyewitness lineups — police include people who look vaguely like their main suspect, but are known to be innocent.
When an analyst is only given two bullets to compare, they’re immediately aware that one is a crime scene bullet and one is a test bullet from a gun that police suspect to be the murder weapon. The analyst knows from the start that police or prosecutors believe the two bullets should match.
At most labs, analysts begin their analysis with this type of “side by side comparison,” in which they look at both bullets under a microscope at the same time. From the outset, it’s a process that can condition even an experienced, conscientious analyst to seek out similarities and overlook discrepancies.
Another bedrock principle of the scientific method is blind review and verification. In the hard sciences, most researchers subject their work to blind review by peers before publication. After publication, other scientists then attempt to replicate the results.
Applied to forensic firearms analysis, this would mean a peer or supervisor should regularly verify each analyst’s work. But it’s important that such reviews be blind — the verifying analyst should not be aware of the original analyst’s conclusions.
That part is critical. A 2020 study by researchers in the Netherlands compared blind versus non-blind reviews in 568 real-world cases. The study found that when reviewers were blinded to their colleague’s conclusions, they contradicted those conclusions 42.3 percent of the time. When they were made aware of a peer’s conclusions prior to reviewing, that figure dropped to 12.5 percent, a discrepancy that highlights the power of suggestion, but also the alarmingly high rate at which two analysts can disagree after viewing identical evidence.
But most labs don’t do blind verification. In his brief in the Cook County case, Gutierrez points out that at the Illinois crime lab used by the prosecution, not only is verification not blind, “the primary analyst will actually set up the microscope for their verifier, focusing their attention on the specific marks relied upon to reach the initial conclusion.” That’s a virtual roadmap for verification.
The review process is supposed to make us more confident about an analyst’s conclusions. But if the verification process isn’t blind, it merely provides false reassurance of an opinion that was never grounded in science to begin with.
Even among the minority of labs that release exculpatory test results, most require both the first analyst and the verifying analyst to agree on an exclusion for that information to be provided to the defendant. After crunching the data from the Ames studies, Gutierrez found such agreement in just 14.5 percent of cases. If those results are an accurate reflection of real world performance — as firearms analysts claim they are — for every 100 times an innocent defendant was falsely accused and for which ballistic evidence should have excluded them, we could expect 14 to 15 defendants to actually be informed of said exonerating evidence.
Moreover, though the verification process is touted as a safeguard against wrongful convictions, in the Ames studies — which again are widely cited by defenders of ballistics matching — the verification process was five times more likely to falsely incriminate defendants than to correctly exonerate them.
If forensic firearms analysis were a true science, there would also be universal standards and criteria for all these processes. The conclusions of an analyst and verifier in one case would be based on the same policies, procedures, and criteria as an analyst's conclusions in any other case.
Instead, Gutierrez explains in the defense brief, different labs take vastly different approaches:
. . . some [labs] verify all conclusions while others verify only identifications and eliminations (those based on individual characteristics), some utilize blind verifications (where the second examiner does not known the conclusion of the first) while others conduct non-blind verifications (the verifier can be aware of the conclusion of the first examiner and even review their notes and documentation); ISP [the lab involved in this case] follows the latter course in each of the preceding divides.
There’s one other interesting takeaway from the Ames studies: As with most pattern matching specialities, forensic firearms analysts claim their expertise comes from training and experience. In fact, they often claim that experience and expertise is sufficient to compensate for the field’s noncompliance with other scientific principles.
Of course, it doesn’t matter how well-trained you are, how much experience you have, or how closely you adhere to the methods and procedures of your field if all of that training, experience, and procedure is premised on nonsense. Returning to our much-loathed metaphor, even the most meticulous, careful, and experienced tarot card reader . . . is still a tarot card reader.
But this argument was also undercut by both of the Ames studies. They found no correlation between an analyst’s experience and training and their proficiency on the tests.
Co-opting the science
After the bombardment of criticism from scientists, criminal defense interests, and reformers, defenders of firearms analysis and other questionable fields of forensics have responded with some rhetorical jujitsu to convince judges that their field has more support in the scientific community than it actually does.
Here, for example, is an excerpt from Weller’s testimony for a Daubert hearing before a federal court in Washington, D.C., which is similar to claims he has made in other cases.
The defense motion starts with the overall premise that forensic science, and specifically firearm and toolmarks analysis, is not scientific because it has not embraced critiques. Constructive criticism is a cornerstone of science and is an essential part of forensic science. However, the motion fails to acknowledge the significance of the research using 3D imaging and computer comparison algorithms.
My original statement describes this body of work and why it provides strong support for the foundations of firearm and toolmark analysis. Some of this research was motivated by and in response to the 2008 and 2009 National Academy of Sciences (NAS) reports. In addition to the research that has been conducted, the formation and participation in the Organization of Scientific Area Committees are also a response and engagement of the professional forensic science community to address these critiques. The characterization that the profession is not paying attention to and attempting to address critiques is unfounded.
There are a few issues with this testimony that are worth addressing. The first is the implication that the forensics firearm community responded favorably and constructively to those late 2000s NAS studies. They responded defensively, just as they have to the subsequent reports from other scientific groups.
The second issue concerns Weller's reference to the Organization of Scientific Area Committees, or OSACs.
After 2008 NAS report, the National Institute of Standards and Technology (NIST) set up a series of working groups to study and assess the various forensic specialties and come up with standards and best practices. These are called OSACs.
NIST is a reputable agency which has traditionally operated on principles well grounded in science. But whether out of a sense of fairness, diplomacy, or to get buy-in from practitioners, law enforcement, and politicians, NIST allowed practitioners of the very fields the OSACs were supposed to be evaluating to serve on the OSAC committees. And because practitioners have much more motivation to join and influence these committees than outside scientists, some of these committees have since been overtaken by practitioners.
This is certainly true of the forensic firearms OSAC. All three chairpersons of that committee, including Weller, are practitioners, with two currently working in law enforcement.
They also quickly wielded their influence. As the defense brief in the Cook County case points out, in preparation for its own 2015 report on forensics, the PCAST asked the various OSACs to provide all of the available research on error rates, competency tests, and other studies into the foundational principles of their fields. The firearms OSAC turned over only those studies showing low rates of error.
Once these committees are captured by practitioners, they can then co-opt the prestige and imprimatur of NIST to claim scientific validation. Where defense attorneys previously argued that no scientific body has yet validated forensic firearms analysis, prosecutors can now point to a reputable scientific body that has provided its stamp of approval — just as Weller did in the excerpt above.
Finally, there’s Weller’s mention of 3D imaging research. For this emerging technology, researchers create 3D maps of the rifling on bullets and the guns that fired them, then enter those maps in a database. They then create algorithms that they hope will one day allow computers to scour these databases to match bullets to guns the way human analysts have claimed to do for decades, but without the high rates of error.
Weller has argued in both the D.C. and Chicago cases that the mere existence of this research is a credit to his field and its commitment to ongoing research. But many of the leading researchers in 3D imaging went into that work precisely because they believe forensic firearms analysis as it exists today isn’t grounded in science and shouldn’t be used in the courtroom.
The scientist spearheading the country’s main 3D mapping effort right now is Alicia Carriquiry, who runs the Center for Statistics and Forensic Evidence at Iowa State University (CSAFE). And in fact, Carriquiry and her colleagues at CSAFE submitted an affidavit for the Cook County case. It was on behalf of the defense. In it, they write:
“Fundamentally, we do not know what the error rate is for these types of comparisons,” adding that “until this is corrected with multiple studies . . . we cannot support the use of this evidence in criminal proceedings.” They conclude, “Our intent in approaching the discipline . . . is constructive: until the extent of the cancer is identified, treatment cannot begin.”
When Weller was asked if he’d read the affidavit from the CSAFE researchers before giving his testimony in Chicago, he responded that he had only “skimmed” it. That may explain why he attempted to credit his field for researchers who likened it to a cancer.
In an interview, Carriquiry told me the memo written by FBI crime lab counsel Agar is “pure hubris.” Moreover, in reference to the Ames I study, she said, “A dispassionate observer would say that they would have made fewer mistakes if they had flipped a coin.”

Weller's attempt to flip scientific critiques of his field upside down and claim them as endorsements is common among practitioners of controversial areas of forensics.
Take the 2009 NAS report, for example. That report did not explicitly call on judges to bar dubious forensics from the courtroom. But that wasn’t the purpose of the report. As a research body, the NAS has no authority to make the courts comply. The point of the report was to draw public attention to areas of forensic that lack scientific support, to encourage more science-based research into those fields’ core premises, and to provide a resource for judges presiding over hearings like the one in Chicago. The report also sought to build a consensus, so it used diplomatic language — some have argued to a fault.
Some prosecutors seized on the diplomatic language, claiming — oddly — that because the report didn't explicitly call on the courts to prohibit pattern matching fields, we can assume the report endorsed their continued use.
This sort of mischaracterizations became so common that Judge Harry T. Edwards, the co-chair of the NAS committee who wrote the report, felt compelled to correct the record in a 2010 speech:
I recently had an opportunity to read several briefs filed by various U.S. Attorneys’ offices in which my name has been invoked in support of the Government’s assertion that the Committee’s findings should not be taken into account in judicial assessments of the admissibility of certain forensic evidence . . .
This is a blatant misstatement of the truth. I have never said that the Committee’s Report is “not intended to affect the admissibility of forensic evidence . . . To the degree that I have commented on the effect of the Report on admissibility determinations, I have said something quite close to the opposite of what these briefs assert.
Edwards has since made this point in numerous other speeches and written comments. Notably, Edwards is not an Innocence Project lawyer or one of those activist scientists that forensic practitioners complain about. He’s the chief emeritus judge for the U.S. Court of Appeals for the D.C. Circuit.
Yet some 13 years after that 2010 speech, a period in which the same speech has been frequently cited in defense briefs, the practitioners of these fields and their advocates in law enforcement continue to misquote Edwards. As recently as last year, Agar wrote in a law review article, “Judge Harry Edwards made it clear that nothing in the report was intended to answer the question whether forensic evidence in a particular case is admissible under applicable law.”
Again, Edwards himself has been clear that he never said anything of the kind.
The impact
It's worth reiterating that in most of these challenges to forensic testimony, judges tend to simply look at what other courts have done then cut and paste a list of citations to opinions that have already certified that particular type of analysis. At most, they might reiterate arguments from prosecution witnesses about low error rates without examining how those rates were calculated.
Hooks's ruling was the sort of thorough engagement with the science that every defendant deserves, but too few get. But it took more than just an unusual judge for Hooks’s ruling to happen.
As it turns out, the Cook County Public Defender’s Office is one of just a few such offices in the country with a division solely dedicated to forensics. “When we decided to challenge forensic firearms analysis, I spent an entire year in which my full time job was to learn everything I could about it,” says Gutierrez. “I read every study I could find, went to every conference I could attend, interviewed every expert I could get to talk to me. That’s what it took to mount one successful challenge, by one office, in one case.”
A typical public defender doesn’t have the time or resources for that sort of training, so most will lack the background knowledge necessary to thoroughly cross-examine a state witness like Weller. In fact, to mount a successful challenge in some of these areas of forensics, a defense attorney essentially needs to become so familiar with the material that they become experts themselves. And for a typical defense attorney carrying two or three times the ABA recommended caseload, that just isn’t possible.
There's also little reason for them to try. If most judges don’t have the patience or will to entertain a request to overturn several decades of case law, most public defenders will conclude — probably correctly — that they'd better serve their clients by focusing on other aspects of their cases.
Hooks’s ruling is specific to the Winfield case. It is not precedent, and the state has already filed a motion asking Hooks to reconsider -- the first step toward an appeal. But the ruling is thorough enough that unless overturned, it seems safe to assume Hooks will rule similarly when future challenges come before his court. Moreover, under Illinois case law, once a state judge has found a field of expertise to be unreliable, it’s easier to mount similar challenges in other courts around the state. And even though the ruling has no controlling authority, each time a court issues a skeptical ruling against this sort of testimony, it gives defense attorneys in other jurisdictions one more case to cite should they decide to bring their own challenges.
One salient criticism of Hooks's ruling is that if it holds and spreads to other city courts, Chicago prosecutors will no longer be able to call forensic firearms analysts to match a specific bullet to a specific gun. That will inevitably make it more difficult to win convictions in shootings, a consequence police and prosecutors are likely to decry, especially in a city with a (sometimes exaggerated) reputation for violence, and where clearance rates for gun crimes are already alarmingly low.
But Hooks's ruling doesn’t preclude police from utilizing forensic firearms analysis in their investigations. They could still use the class characteristics of guns and bullets to eliminate suspects and to help them decide which suspects merit more investigation. If they still believe in the ability to pair a specific bullet with a specific gun, they can continue to use that information to guide their investigations as well. It just means that those investigations will need to find other evidence.
Even if Hooks's ruling were to become the dominant case law across the country, it also doesn't mean forensic firearms analysis will never reach the point where it merits inclusion in criminal trials. Even critics of ballistics matching have told me that the work researchers like CSAFE are doing could result in algorithms that can cross reference the marks on bullets against the databases they're creating and match a bullet to a gun with a calculable margin for error.
But according to every major scientific body to evaluate forensic firearms analysis, we aren't there yet. Under a fair and just system, the fact that these unproven methods have already been used for so long would be a source of embarrassment. Instead, the fact that the courts are already waist-deep in forensic firearms junk science has become an excuse to continue to wallow in it — instead of freeing themselves from it.
Would prohibiting forensic firearms analysis from trials make it more difficult to win convictions? It seems likely. But as we've seen with the hundreds of DNA exonerations to date, ensuring the evidence used in court is backed by sound science is the difference between convicting the correct person for a crime and convicting . . . just anyone.
I'm rapidly coming to the point that forensic labs should be permanently decoupled from law enforcement.
Superb, thorough, convincing. Thank you.